10.3.1 リスクファクター間の従属性、10.3.2 従属性の取り扱い、10.3.3 多次元分布、10.3.4 従属性の尺度
この記事では、10.3節のうち、コピュラが登場する直前まで。
10.3.1(リスクファクター間の従属性)は特に言うことはない。
10.3.2(従属性の取り扱い)はあまり理解できなかった。「構造的モデル」と「統計的モデル」というのが具体的にどういった函数型を示しているのかが分からなかったためだ。
数理モデルの話をしている以上、XとYの従属性とは究極的にはXとYの同時分布に帰着するはずである。「特定された因果関係に基づいて関連性の表現をするモデルを構造的モデル」「観察された統計的性質に基づいて関連性の表現をするモデルを統計的モデル」という説明からは、
構造的モデル:確率変数の組T=(T1,・・・,Tn)とその同時分布があり、X、YはそれぞれTの函数X(T)、Y(T)として表される
統計的モデル:X、Y以外の確率変数を含まない同時分布で表される
という解釈ではどうかと思った。
この場合、構造的モデルはT1=X、T2=Yの場合として、統計的モデルの一般化になっている。なので、とりあえず簡単な統計的モデルに限って話を進めるという風にこの小節を自然に読むことができる。
しかし、この解釈で読み進めた場合、以下の疑問が起こった。
・10.3.4の例10.8、10.9は統計的モデルというよりはむしろ構造的モデルの単純な例(X=T、Y=T^2)である。
・相関係数やコピュラに関する説明/議論は、構造的モデルを想定した場合になにか不都合が起こるのか。特に違いはないように思える。
従って、上の解釈は誤りで、X、YがそれぞれTの函数で表される場合も統計的モデルに含むと思われる。
すると、構造的モデルの「特定された因果関係に基づいて関連性の表現をする」というのはどういう表現のことなのだろう。
10.3.3(多次元分布)は特に言うことはない。
10.3.4(従属性の尺度)について。
例10.8はもう少し一般的に、X1の密度関数(fとする)が偶関数であるときに成立する。なぜなら、この時xf(x)、x^3f(x)は奇函数であり、その積分(つまりE(X)、E(X^3))は0になるからである。
例10.10は考えたが解けなかった。
ケンドールの順位相関係数を簡単な分布で計算してみようと思ったが、signの積分をどうすればよいか分からなかった。代数だとsignX = X/|X| (絶対値で割る) としてしまえば割とうまくいくんだが、これだと積分がとても難しい。さらに登場する確率変数も4つあり、うち2つは関数関係を持っていたりして・・・。
検索してみた感じだと、積分してみようという話は見つからなくて、サンプルについて集計する話ばかりであった。
この係数がどういう分布に関して優位性があって、どういう分布に関して弱いのか、分からない。
#2011/3/20追記 10.3.7(1)にコピュラが求められた場合の積分の算式が記載してあった。証明等はまだ考えていないが、分からない気がする。
スピアマンの順位相関係数は具体的な分布に関して計算可能である。
F(X)がU(0,1)に従うので分母のV(F(X))は1/12であるし、分子の計算においてもE(F(X))は1/2なので、E(Fx(X)Fy(Y))さえ計算出来ればよい。
まず、X,Yが独立の時はこの係数は0になる。
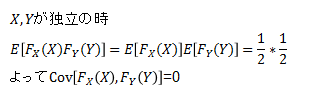

あとはテキストに書いてあるようなメリット・デメリットがあるのだろう。
しかし1点、これは書いておかないとフェアでないと思うことがある。
それは、この係数も前述の例10.8に関して、係数0となることだ。

結局全て、コピュラを導入する前の当て馬なのかと感じてしまった。
0 件のコメント:
コメントを投稿